Audio Annotations
Audio annotations are essential for training and developing speech recognition systems such as virtual assistants, chatbots, security systems with speech recognition, etc. Additionally, it can be used to create transcripts or subtitles for video recordings.
What we do: An overview
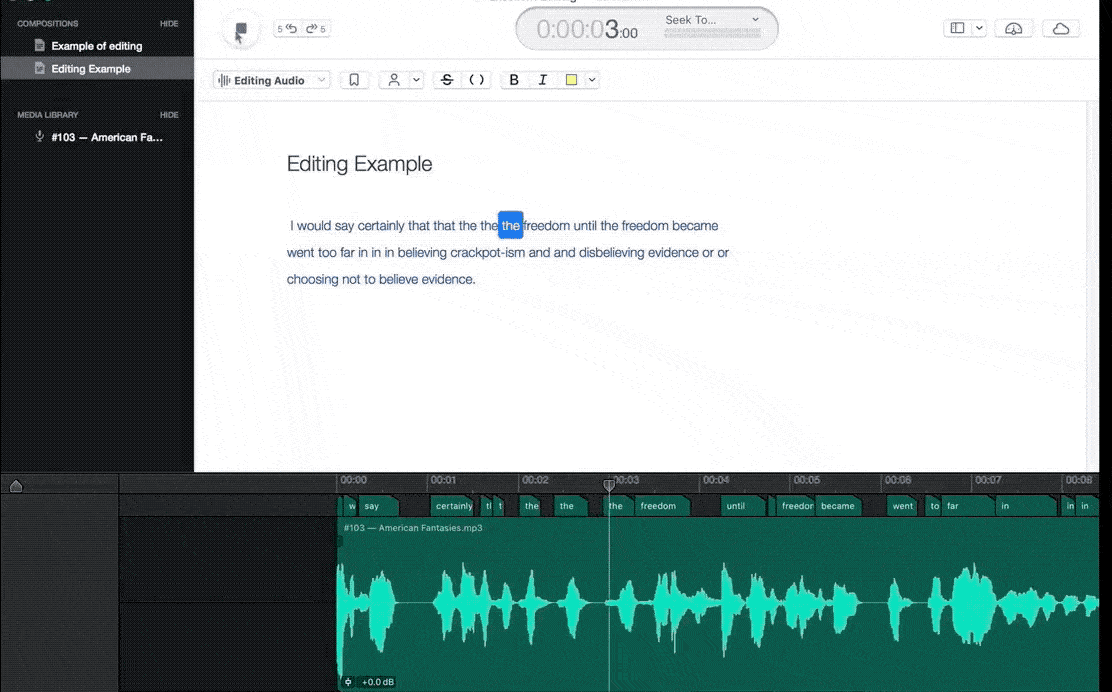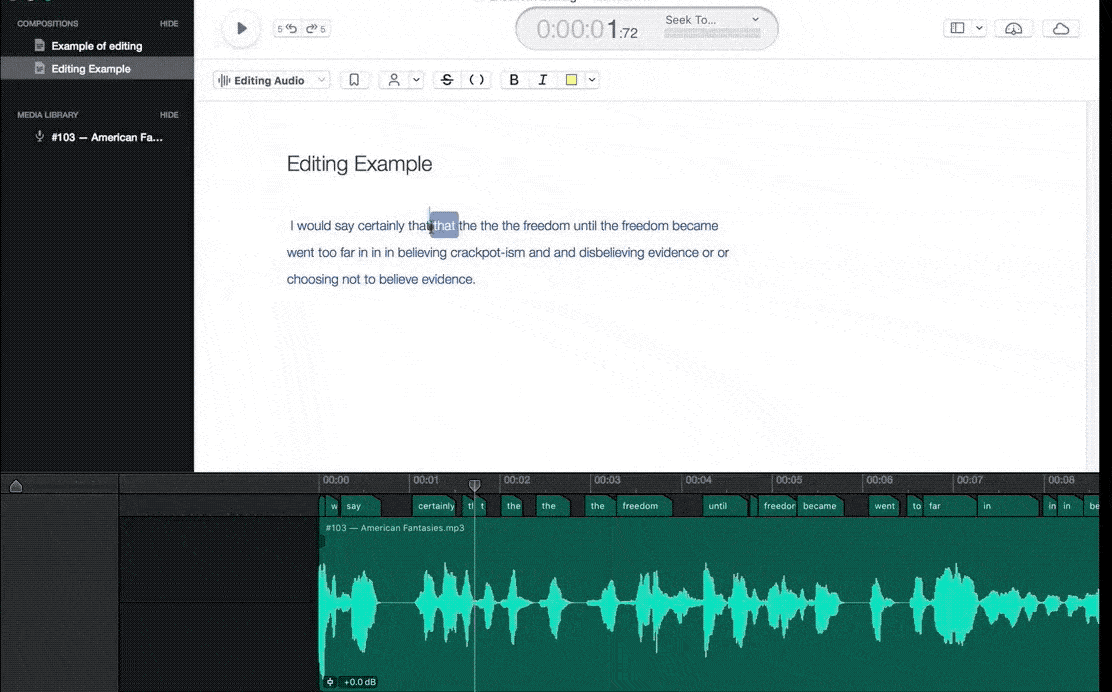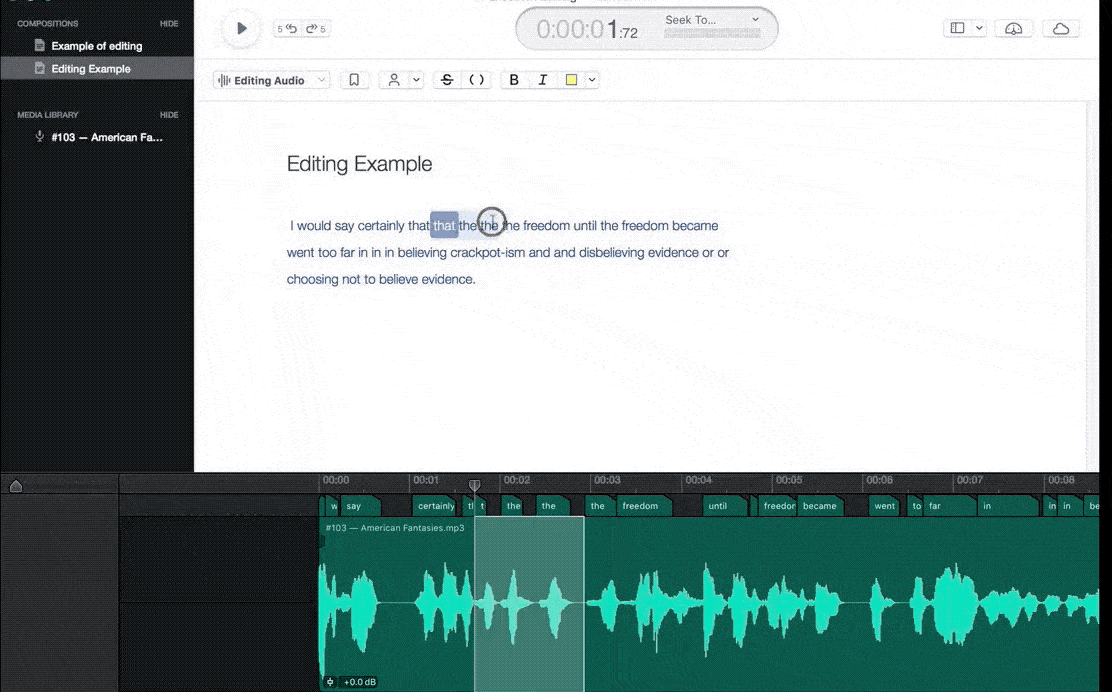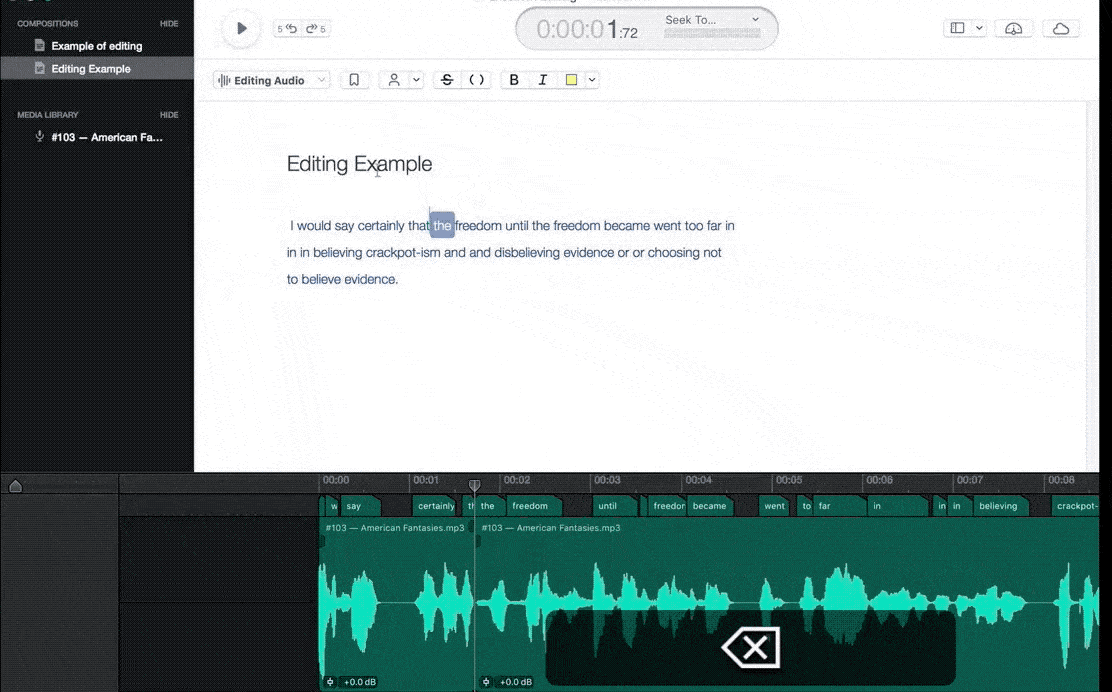
In this process, we make sure to label all of the audio files clearly and concisely. We try to listen to the audio files multiple times before annotating them. This helps us catch any important details that we may have missed the first time around.
We focus on the details when making annotations Include everything from the emotions being expressed by the speaker to the different sounds that are present in the background noise. It involves the classification of audio components in a machine-understandable format.
We use different types of audio annotations within computer vision:
Virtual assistant
With our fine dataset quality, the virtual assistants can be trained to develop a voice assistant that can process the request accurately and respond quickly for a better customer experience.
Text-to-speech modules
This technology has to be trained on annotated audio files to develop a text-to-speech module that can seamlessly convert digital text into natural language speech.
Chatbots
Chatbots are an integral part of customer support. Chatbots should be trained to interpret users’ words and phrases using annotated audio files to simulate a natural conversation with humans.
Automatic Speech Recognition
It is all about transcribing spoken words into written text. “Speech Recognition” itself refers to the process of converting spoken words into the text.