Image Annotations
Image annotation is a vital part of training computer vision models that process image data for object detection, classification, segmentation, and more.
What we do: An overview
In this process, we manually label the images in a given dataset to train machine learning or deep learning models to replicate the annotations without human supervision. Amongst the plethora of image annotation tools out there, we use the right tool which requires a deep understanding of the type of data that is being annotated and that fits our use case.
We pay particular attention to the modality of the data, the type of annotation required and the format in which annotations are to be stored. We set the standards high and provide the quality image data which lays the foundation for neural networks to be trained, making it one of the most important tasks in the AI project.
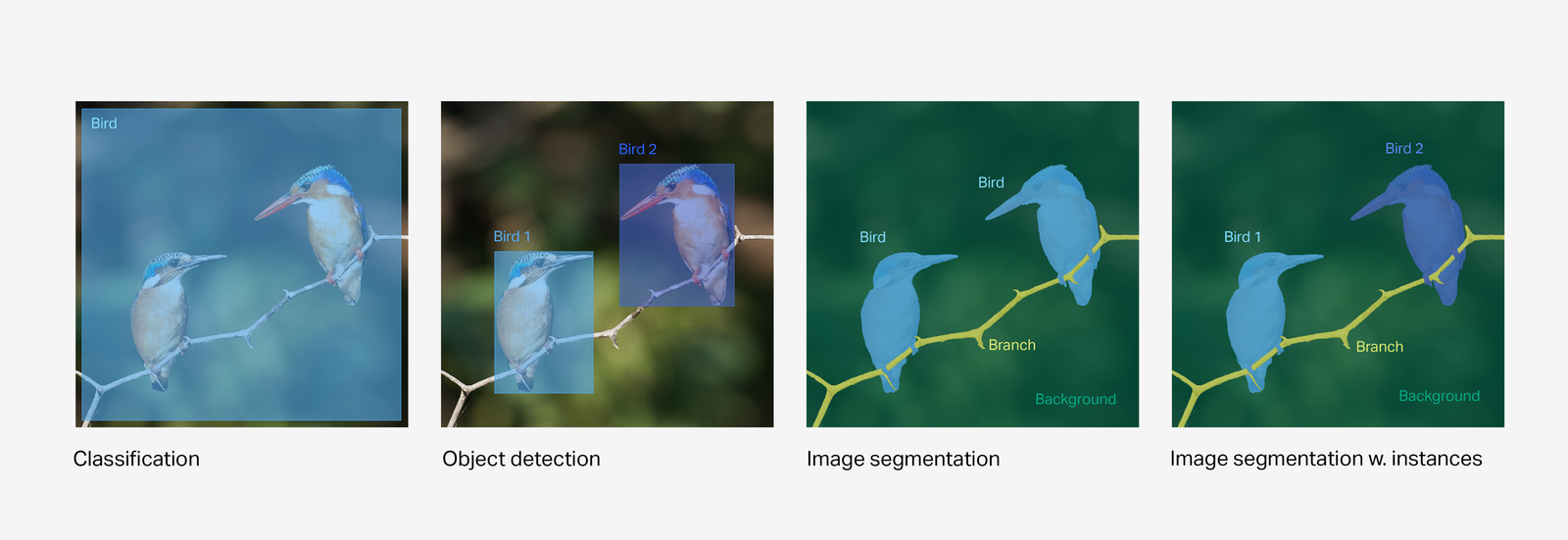
We use the three most common image annotation types within computer vision:
Classification
With whole-image classification, our goal is to simply identify which objects and other properties exist in an image without localising them within the image.
Object detection
With image object detection, our goal is to find the location of individual objects within the image.
Image segmentation
With image segmentation, our goal is to recognize and understand what's in the image at the pixel level, where a pixel in an image is assigned to at least one class, as opposed to object detection, where the bounding boxes of objects can overlap. This is also known as semantic segmentation.
We use various types of image annotation shapes to segment the images in the form of bounding box, polygon, polyline, keypoint, 3D cuboid etc.